Supplementary Material: https://openaccess.thecvf.com/content/CVPR2021/supplemental/Yang_Causal_Attention_for_CVPR_2021_supplemental.pdf
Introduction
Attention Mechanism을 활용한 모델을 Large-scale Dataset에 훈련시킨 연구들이 Vision-Language Tasks에 훌륭한 성능을 보이고 있다.
하지만, Attention 기반의 Vision-Language 모델들의 Attention Weights는 Unsupervised. 즉, 1) (Word, Region)의 Pair로 된 데이터 or 2) Region 간의 Relationship에 대한 정보를 기반으로 학습하는 게 아니기에, Dataset Bias에 의해 Spurious Correlation을 학습하게 된다.

Figure 1을 예시로 보면, Train Dataset 내 유사한 이미지에 "Person riding horse"라는 캡션만 많이 달린 경우, "Person driving carriage"는 무시되고 Test시에도 여전히 self-attention은 "Carraige"라는 정보는 무시하게 된다.

이런 Dataset Bias는 Pre-training시에도 문제를 일으킨다. Figure 2에서는 Pre-training Dataset에 많이 존재한 Concept에 의해 잘못된 답을 내놓는 예시들을 볼 수 있다.
저자들은 Pre-training Dataset Scale을 무작정 키우는 것이 해결책이 아니라고 얘기한다. Dataset Scale이 커질수록, 특정 Concept이 더 많이 나타나고 Attention에 더 악영향을 미칠 것이라고한다. 그럼 결국 Dataset Bias에 대한 해결책을 마련해야하는데, 이런 Dataset Bias는 Causal Inference 관점에서는 Confounder가 존재하기에 발생한다.
저자들은 여기서 Dataset에 많이 존재하는 Concept, 즉, Common sense 를 Confounder 라고 가정한다.

Figure 3을 다시 그리면, 아래와 같이 나타낼 수 있다.
이는 Dataset이 형성되는 관점에서 본 Causal Graph로 보면 될 것 같다.

그럼 위와 같이 Causal Graph를 가정했다면, Back-door adjustment로 Back-door path를 제거하면 되는 게 아닌가?라는 질문을 던질 수 있다. 하지만 그렇게 접근하기 위해선 Confounder에 대한 Detail한 가정이 필요한데, 이런 가정은 Domain-knowledge가 많이 요구되고, 어렵다. 따라서, 저자들은 Confounder에 대한 가정이 필요없는 Front-door adjustment로 deconfound를 시도했다.
Causal Attention
Attention in the Front-Door Causal Graph
Dataset 관점의 Figure 3와, Task 관점의 Figure 1의 Causal Graph를 같이 그리면, 아래 그림과 같이 나타낼 수 있다. (아래 그림은 저자들이 예시를 든 대로, VQA 태스크를 가정하고 예시로 그린 것이며 X와 Z의 구체적인 예시는 태스크, 인풋 데이터, 뽑아낼 피쳐에 따라 유동적으로 생각하면 된다.)

위 그림과 같이 Causal Graph를 가정하면, 우리는 Dataset 관점의 Causal Graph(그림의 윗부분)에 대해 자세히 몰라도 Front-door adjustment를 통해 P(Y|do(X))를 계산해낼 수 있다.
Back-door adjustment, Front-door adjustment에 대해 익숙하다면, 아래의 수식 전개는 자연스럽게 느껴질 것이다.
(Supplementary Material을 보면 더 쉽게 이해할 수 있다.)

저자들은 IS-Sampling, CS-Sampling의 이름을 다음과 같은 이유로 정했다:
IS-Sampling (In-Sample Sampling)은 현재 Input Sample X에 대해 selected knowledge z를 뽑기 때문
CS-Sampling(Cross-Sample Sampling)은 Dataset 내 Sample 들로 계산해야하기 때문
위에서 얻은 수식으로부터, NWGM을 적용하면 아래의 결과를 얻을 수 있다.

In-Sample and Cross-Sample Attentions
앞서 (5)까지는 일반적인 NN의 관점에서 IS-Sampling과 CS-Sampling을 정의했다면, Attention Mechanism에 맞게 Q-K-V Operation을 통해 Z hat과 X hat을 표현할 필요가 있다.

Causal Attention Module은 Figure 4와 같이 그릴 수 있다. 먼저, IS-ATT에 대해 다뤄보자.
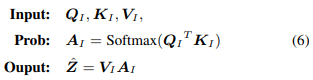
이 케이스에서는 Q_I는 Input Sample의 Embedding Query Vector, K_I, V_I는 각각 Input Sample로부터 뽑은 Feature이다. 또한, 아래와 같이 나타낼 수 있다. (일반적인 Attention Score를 계산하듯이)
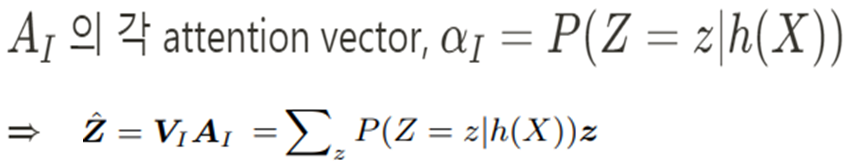
CS-ATT의 경우는 똑같이 아래와 같이 계산 가능하며,
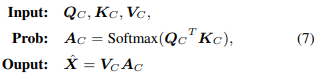
Q_C는 Other Sample의 Embedding Query Vector, K_C, V_C는 각각 Global Dictionaries compressed from the whole training dataset이다. A_C는 앞서 IS-ATT와 같은 방식으로 계산한다.
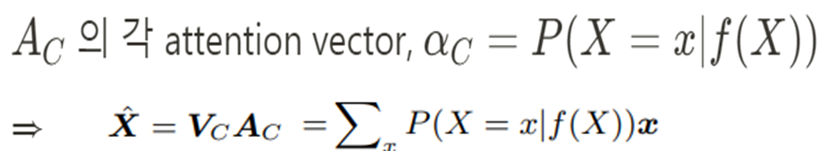
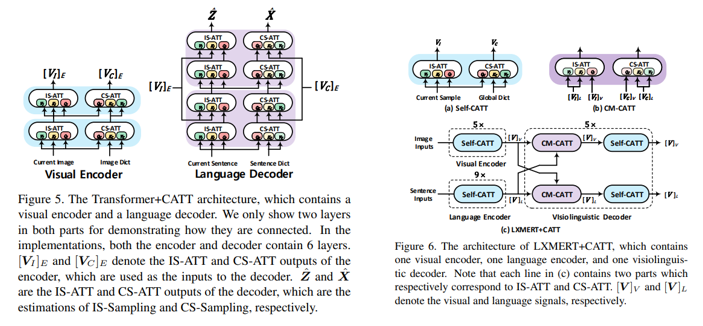
CATT in Stacked Attention Networks
저자들은 해당 모듈을 트랜스포머와 LXMERT에 구현하고 실험했다.
Experiments
이 논문에서는 Vision-Language Tasks를 위해 Causal Attention이라는 모듈을 제시했으므로, Image Captioning(IC), Visual Question Answering(VQA), Graph Question Answering(GQA), Vision-Language Pre-Training(VLP) 등 태스크에 대한 실험을 진행했다.
각 태스크에 대해 다양한 결과들을 테이블로 제시하고있으나, 각 태스크에 대한 결과는 성능이 잘나왔다 or SOTA다. 등의 결과와 우리 모델이 트레이닝 시간이 더 적다. 등의 결과이다.
(이 게시물에선 해당 테이블들을 하나하나 살펴보는 것은 생략하고, 아래 Figure로 CATT를 적용한 경우가 더 Attention을 잘 수행하고 있음을 보여줌으로 대체하겠다.)

Conclusion
많은 Causal Inference와 관련된 논문들은 Hidden Confounder가 없다고 가정하고 접근하는 경우가 많고, Back-door Adjustment를 활용한 Method를 제시한다. 이게 실제 문제에 적용할 수 있을까? 라는 의문도 많고, 실제 실험도 Simulation Dataset 또는 Semi-Synthetic Dataset에 대해서만 다루고 있어 실제 문제와는 좀 거리가 있는 느낌을 받았다.
개인적인 의견으로는 이 논문처럼 Confounder에 대한 가정 없이 Front-door Adjustment를 활용한 Method가 실제 문제 해결에 좀 더 적합할 것으로 생각한다. (물론, Domain Knowledge를 바탕으로 Causal Graph를 잘 가정하고, 해당 Graph에서 나타나있는 요소들을 Data로 모두 수집하면 Back-door Adjustment도 가능할 것이지만, General한 Method로 사용하긴 어려울 것으로 생각한다.)
[참고 자료]
[1] Hao Tan and Mohit Bansal. Lxmert: Learning crossmodality encoder representations from transformers. arXiv preprint arXiv:1908.07490, 2019