Title: Show and Tell: A Neural Image Caption Generator (CVPR, 2015)
최근 Causal Inference에 관심이 많이 가서, CVPR 2022에 게재된 Show, Deconfound and Tell: Image Captioning with Causal Inference 라는 페이퍼의 레퍼런스를 훑어보다 읽게 됐다.
Introduction
Image Captioning(IC) 분야는 이름 그대로 이미지를 입력받아 해당 이미지를 설명하는 문장을 생성하는 태스크다. 일반적으로, 우리가 컴퓨터 비전 분야의 대표적인 태스크 하면 떠올리는 image classification, object detection 보다 어려운 작업이라고 할 수 있다.
주어진 이미지에서, object만 다루는 게 아닌 각각이 어떤 관계인지, 행동이나 특성에 맞게 표현해야 하고, 이를 언어로 표현해야 하기 때문이다. (이를 위해서는 비전 모델뿐 아니라 언어 모델 또한 요구된다.)
저자들은 당시 기계 번역 분야에 활용된 다음과 같은 아이디어에 영감을 받았다:
- Source Sentence를 Encoder에 입력해 Context Vector로 변환하고, 이를 다시 Decoder를 통해 Target Language로 번역한다.
(Seq2Seq와 같은 구조를 떠올리면 될 것 같다.)
기계 번역에서는 Encoder와 Decoder로 모두 RNN을 사용했다면, 저자들은 IC 문제에서 입력 이미지에 대한 rich representation을 얻기 위한 Encoder로 CNN을 사용했다. 따라서, 대략적인 구조는 다음 그림과 같다.

Method
기계 번역의 objective function와 유사하게, 저자들은 IC 문제의 Objective function을 다음과 같이 제시한다:
( I는 입력 이미지, S는 그에 맞는 적절한 설명을 나타낸다.)
또한, chain-rule에 의해 당연히 다음과 같은 식도 얻을 수 있다.
해당 논문이 제시된 시기는 아직 Transformer(2017)이 제시되기 전으로, LSTM을 Decoder에 활용해 다음 그림과 같은 구조를 갖는다.
훈련을 위한 Loss Function은 negative log likelihood를 활용했다.
Inference
학습을 마친 후, Inference에는 두가지 방법을 제시하고 있는데,
1. Sampling : 각 확률 값(p1, p2, ...)에 따라 각 단어를 결정하는 방법
2. BeamSearch : 각 step에서 likelihood 값이 높은 k개의 sentence만을 유지하며, 다음 step으로 반복하면서 확장하는 방법
논문에서 제시하는 실험은 BeamSearch를 사용했다.
Experiment Result
실험에 사용된 데이터 셋과 size는 다음과 같다.
SBU를 제외하고는, 각 이미지에 5개의 sentence가 라벨링 된 데이터 셋이다. SBU는 Flickr에 업로드된 이미지와 이미지의 owner가 작성한 설명으로 구성된 데이터 셋으로, 더욱 noisy하다.
대표적인 평가 지표에 대한 실험 결과는 다음과 같다.
저자들은 이런 지표에 대한 성능과는 별개로 사람이 직접 평가한 결과를 제시한다. Ground Truth(GT)에 비교해, 점수가 현저히 낮으며(이전 모델들 보다는 뛰어나다.) 저자들은 다른 BLEU가 완벽한 Metric이 아님을 언급한다.
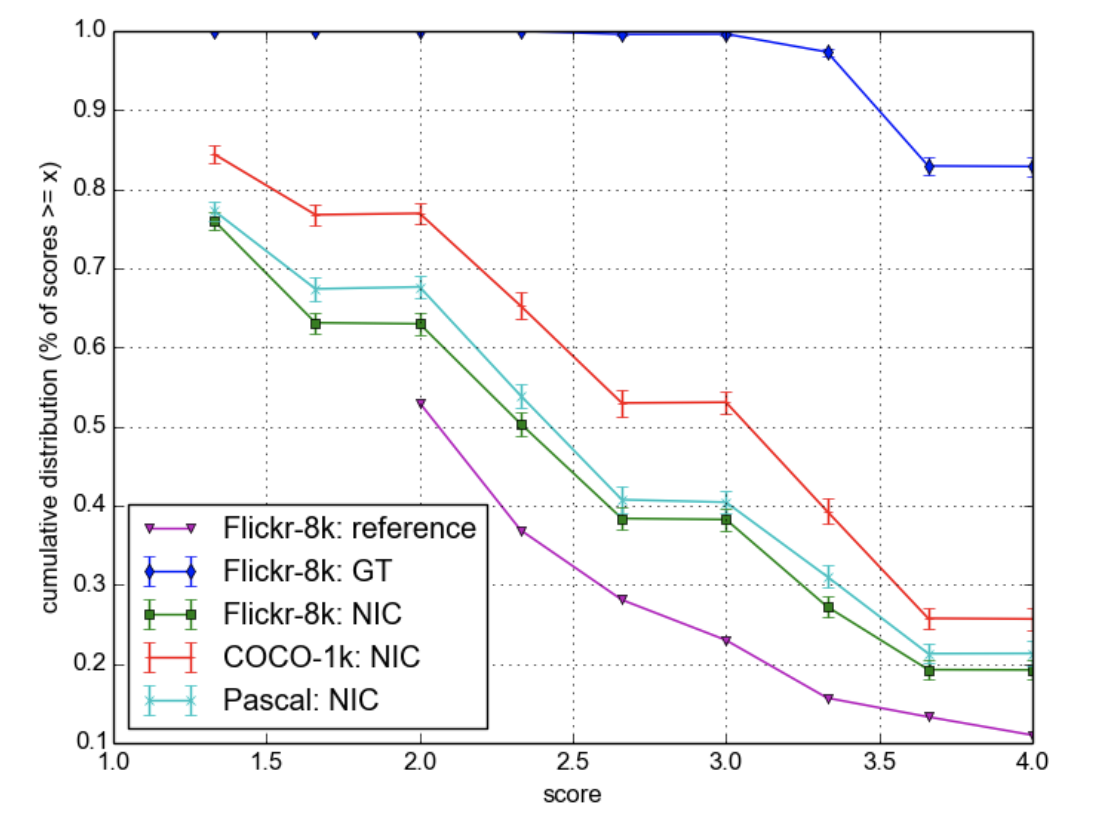
Conclusion
저자들이 제시하는 해당 논문의 main contirubution은 다음과 같다:
1. IC 분야에, fully tranable한 end-to-end system을 제시했다.
2. Vision과 Language Model의 SOTA 모델들의 각 부분을 결합해 만들었기에, pre-trained model의 이점을 취할 수 있다.
3. 기존 SOTA보다 훨씬 나은 성능의 SOTA를 달성했다.
추가적으로, Dataset이 커지면 Model의 성능이 좋아진다는 점과, 대표적인 Metric에 대해 사람보다 점수가 높은 경우가 있지만 사람이 평가한 결과에 대해서는 그렇지 않음을 통해 Metric 연구에 대한 필요성도 보였다.
개인적으로는 잘 읽히기도 했고, 어떤 목적에 따라 데이터 셋, 실험 방식을 설정한 지에 대한 설명이 잘 된 논문이라고 생각이 들었다!
나도 다음에 논문을 작성하게 된다면, 읽는 사람이 이런 느낌을 받으면 좋겠다.
[참고 자료]
[1] Seq2Seq Paper, https://arxiv.org/pdf/1409.3215.pdf
[2] BeamSearch, https://littlefoxdiary.tistory.com/4