반응형
개요
Title : Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery,
(Information Processing in Medical Imaging(IPMI), 2017)
- Introduction
- Method
- Experiment
- Result
- Conclusion
Introduction
- 의료 이미지를 보고 단순히, 건강함 or 질병 보유(0 or 1)를 나타내는 것보다 어느 부분이 이상한 지를 짚어주는 것이 훨씬 많은 정보를 제공

- Unsupervised Learning
- 데이터 불균형 문제 : 의료나 제조 현장에는 Normal 데이터는 많지만, Abnormal 데이터는 적음
- Annotation : 전문가들이 직접 라벨링을 해야함 ⇒ 시간 + 비용 소요 + 다른 판단
- Anomaly Detection
- GAN 활용 ⇒ Vanilla GAN이 아닌 DCGAN을 채택
- 새로운 Anomaly Scoring을 제시 : 기존의 GAN과는 반대로 Image Sample 에서 Latent Vector로의 매핑을 활용하는 새로운 Anomaly Score를 제시
Method
전체 과정은 아래처럼 두 부분으로 나뉨
- Model Training (좌)
- Detection of Anomalies (우)
Model Training
먼저, 기본적인 GAN의 학습
Normal Data (Healthy Data, 건강한 상태를 촬영한 이미지)만을 학습해, G는 정상 데이터의 분포를 모방해 어떤 Latent Noise Z를 입력으로 받아도 정상 데이터를 생성.
Value function은 아래와 같음. ( 일반적인 GAN과 동일 )
(x : Data Sample, z : Latent Vector)
- Discriminator : Fake Sample과 Real Sample을 구분하기 위해 학습
- Generator : Discriminator가 Real Sample과 구분할 수 없는 Fake Sample을 생성하기 위해 학습
Mapping
- 기존의 GAN은 학습된 Generator G에 Latent Vector로 입력해 Data Sample을 생성 가능
- Data Sample이 어떤 Latent Vector로 부터 생성될 지는 추론할 수 없음.
Invert Mapping
- 저자는 입력된 Test Data X의 Latent Vector를 찾기 위해 Latent Space 상에서 Latent Vector를 random하게 설정하고, 그에 대응되는 Data Sample을 반복해 찾는 방법을 사용
- 설정한 N번 만큼 시행하면서 Test Data X에 가장 잘 대응되는 Latent Vector를 찾음 (두 개씩 비교하면서 가까운 Latent Vector로 업데이트 )
Anomaly Scoring
- 앞서 Invert Mapping으로 찾은 Latent Vector를 활용
- Residual Loss :
- Discrimination Loss :
- Anomaly Score = Residual Loss + Discrimination Loss
- Anomaly Score가 특정 임곗값 보다 높으면 Abnormal로 판단
Experiment
임상의 고해상도 망막 사진을 데이터로 사용
비교 대상
- aCAE (adversarial Convolutional AutoEncoder) : Residual Loss와 Discrimination Loss가 결합된 유사한 Anomaly Score를 사용
- GANR : AnoGAN과 형태는 같지만 Discrimination Loss만 활용해 Anomaly Detection
- PD : DCGAN의 Discrimination Score를 그대로 활용해 Anomaly Detection
실험 결과
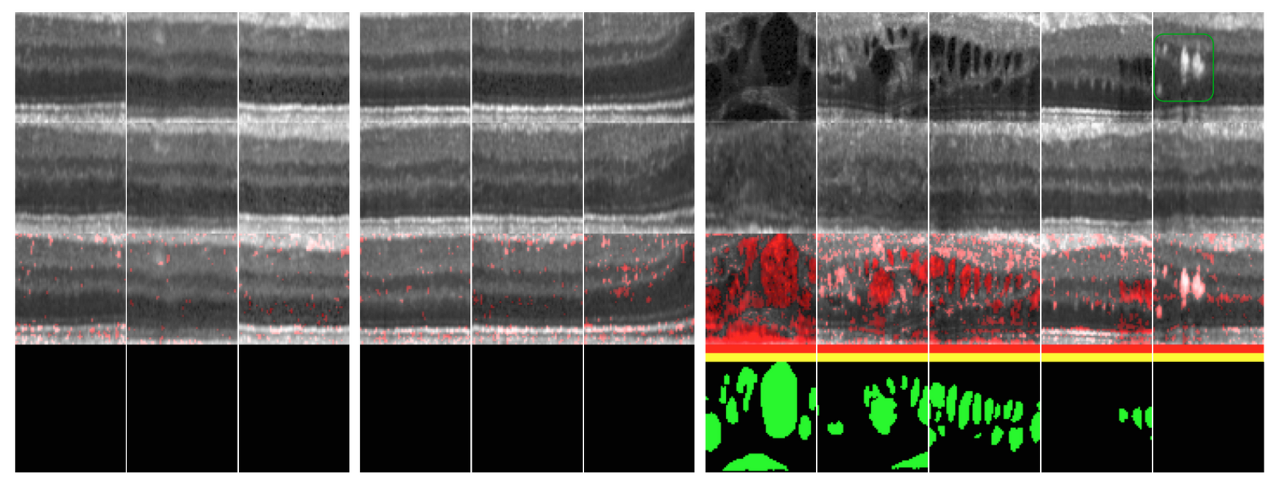
- 마지막 Column은 과반사 초점이라고 부르는 케이스로 ⇒ Retinal Fluid가 나타나지 않아 일반적인 방법으로 식별이 힘듦에도 불구하고, 이상 식별
Result
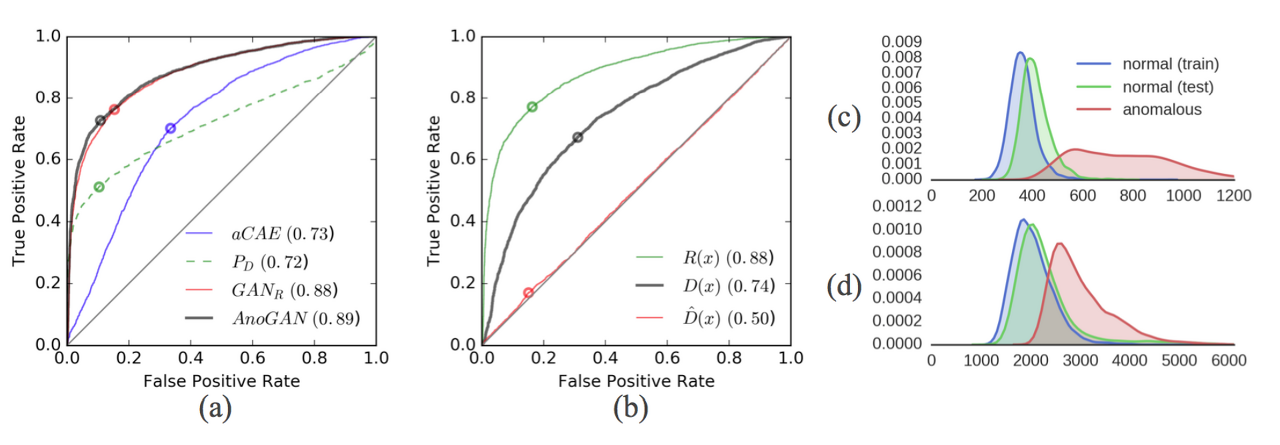
(a) AUROC 값을 기준으로 AnoGAN이 가장 우수한 성능
(b) GANR보다 AnoGAN이 abnormal data에 대한 Discrimination Loss가 큼
(c) Residual Loss 분포 => abnormal data에서 큰 값의 분포
(d) Discriminator Loss 분포 => abnormal data에서 큰 값의 분포

- aCAE : Runtime 부분에서 좀 더 나음, 하지만 이상치 탐지 Performance가 좋지 못함
- PD : 다른 비교군에 비해 Performance가 좋지 못함
- GANR : AnoGAN 과 Performance가 비슷, 지표마다 다름. ⇒ Discrimination Loss만 사용하는 것도 이점이 있다.
Conclusion
- Unsupervised Anomaly Detection
- Data Imbalance 문제 해결
- Labeling 소요를 해소
- Anomalies를 Detect 할 수 있음
- 후속 연구
- f-AnoGAN(2019), TAnoGAN(2020), GAN Ensemble(2020) 등 다양한 연구로 이어지는 중
반응형