Paper: https://arxiv.org/abs/2303.08730
DiffusionAD: Norm-guided One-step Denoising Diffusion for Anomaly Detection
Anomaly detection has garnered extensive applications in real industrial manufacturing due to its remarkable effectiveness and efficiency. However, previous generative-based models have been limited by suboptimal reconstruction quality, hampering their ove
arxiv.org
Introduction
해당 페이퍼는 Diffusion을 활용해 Unsupervised Anomaly Detection Task를 수행한 내용을 담고 있다.
Unsupervised Anomaly Detection Task는 크게
1) Feature embedding-based methods
2) Generative model-based methods
로 나눌 수 있는데,
1)은 Pre-trained dataset과 실제 Inference시 dataset의 distribution이 다른 경우에 성능 저하가 발생하며,
2)는 복원 오차를 활용해야하는데,
2-1) abnormal regions를 제대로 reconstruction 해버리거나
2-2) normal regions를 coarse-reconstruction 해 성능 저하가 발생한다. (복원 오차가 커져 False Positive가 발생한다.)
이 페이퍼는 Diffusion을 활용하고 있으니,
두 methods 중 2)의 methods에 해당하며 언급한 두 문제를 해결함은 물론 Diffusion 모델의 느린 Inference 속도까지 극복했다고 한다. (Introduction 부분의 Figure 1과 2를 보면 다른 모델과의 비교를 통해 위 내용을 간단히 확인할 수 있다.)

Method
Architecture
모델의 아키텍쳐는 Figure 3에서 볼 수 있듯이, Reconstruction Sub-network와 Segmentation Sub-network로 구성된다.
이 아키텍처에서는 일반적으로 정상 샘플만을 학습시키는 방법들과 달리, Anomaly Synthetic Strategy 파트에서 설명한 방법대로, synthetic anomaly를 같이 활용하며 입력 이미지를 normal(y=0) 또는 anomalous(y=1)로 정의한다.
(Anomaly Synthetic Strategy 파트를 먼저 읽어보는 게 더 좋을 것 같다.)
Reconstruction Sub-network
Reconstruction은 Diffusion Model을 활용한다.
Diffusion forward process대로 원본 이미지에 random time step t만큼의 noise를 추가하고 x_t를 얻고, Noise가 얼마나 추가됐는지를 예측하면서 학습한다.
이렇게 학습한 Reconsturction Sub-network를 활용하면 the anomaly-free reconstruction ˆx0 을 구할 수 있다.
(학습 과정에서는 Iterative하게 구하는 것 같다. Inference시는 뒤에서 설명할 One-step Denoising 방식을 사용한다.)
Segmentation Sub-network
Segmentation은 U-Net like architecture 활용한다.
1) 원본 이미지 x0과 2) Reconstruction Sub-network를 통해 얻은 ˆx0를 channel-wise concatenation해 입력으로주고, 모델은 두 인풋 1)과 2)의 inconsistencies와 commonalities를 활용해 pixel-wise로 anomaly score를 예측하도록 학습한다. (Loss Function은 아래와 같다.)
Norm-guided One-step Denoising
Reconstruction시 발생하는 문제를 해결하고자, 저자들은 One-step Denoising과 Norm-guided Denoising이라는 내용을 제시한다.
One-step Denoising
Diffusion의 샘플링 방식대로, Iterative 하게 Time Step T부터 0의 이미지를 Reconstruction하기에는 속도가 매우 느리기에 AD Task에는 적합하지 않다.
속도 문제를 개선하기 위해, 저자들은 아래의 식 (6)을 통해 One-step denoising이 가능하다고 한다.
(더 알아보니 아직까지 Generation과 관련해서는 Iterative approach가 여러 지표에서 훨씬 우수한 것 같고, 이런 Direct approach는 연구 대상인 것 같다. 여기서 다루는 문제는 AD task라 이렇게 해도 괜찮은듯..)

Norm-guided Denoising
이 부분에서는 Introduction에서 얘기한 Generative model-based methods의 두 문제를 해결하기 위한 방안을 제시했다.
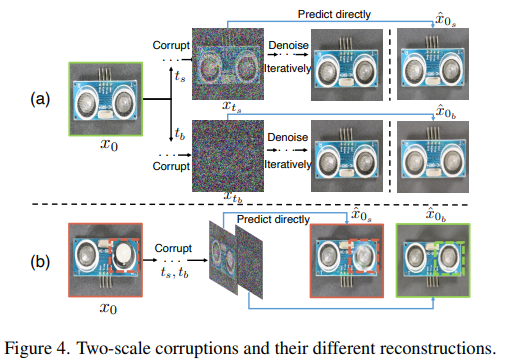
추가적으로 다음과 같이 작고, 큰 Time step을 나눠(tb > ts) 인사이트를 제공한다.
1) 작은 Time step의 Noise를 추가한 경우 Denoise시, Fine-grained recosntruction이 가능하지만, Anomalous Region이 큰 경우 그대로 복구해버림.
2) 큰 Time step의 Noise를 추가한 경우 Denoise시, Anomalous Regions를 잘 복구하나 coarse-reconstruction.
따라서, Figure 4와 같이 상대적으로 noise를 더 많이 추가한 이미지의 denoise 결과를 guide로 작은 time step의 denoise 과정에 활용해, Fine-grained Reconstruction을 달성하면서도, Anomalous Region이 큰 경우 발생하는 문제를 해결한다.
Anomaly Synthetic Strategy
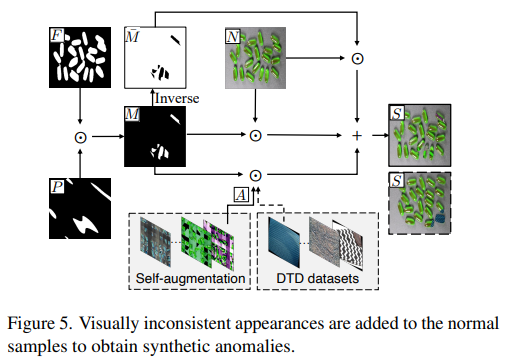
Figure 5는 Normal Sample을 통해 Synthetic anomalous sample을 구하는 과정을 담고있다.
랜덤으로 불규칙하게 생성한 Perlin Noise P와 [2]를 활용해 얻은 Foreground F를 곱해 Noise mask M을 구한다.
(Textural Dataset에 대해서는 foreground를 찾지 않고, 이미지의 random part를 F로 사용한다.)
The appearance of visual inconsistencies A (Anomalous가 어떻게 생겼는지?로 생각하면 될 것 같다.)를 만들어주기 위해서는 self-augmentation과 DTD dataset에서 뽑은 샘플을 사용한다.
마지막으로, 위의 과정에서 Anomalous의 영역과 Anomalous를 만들었으니 Normal Sample에 해당 결과들을 활용해 Synthetic anomaly S를 구한다.

Experiments
MVTec, VisA, DAGM, MPDD 데이터셋에 대해 실험을 진행했다.
Anomaly Detection and Localization Results
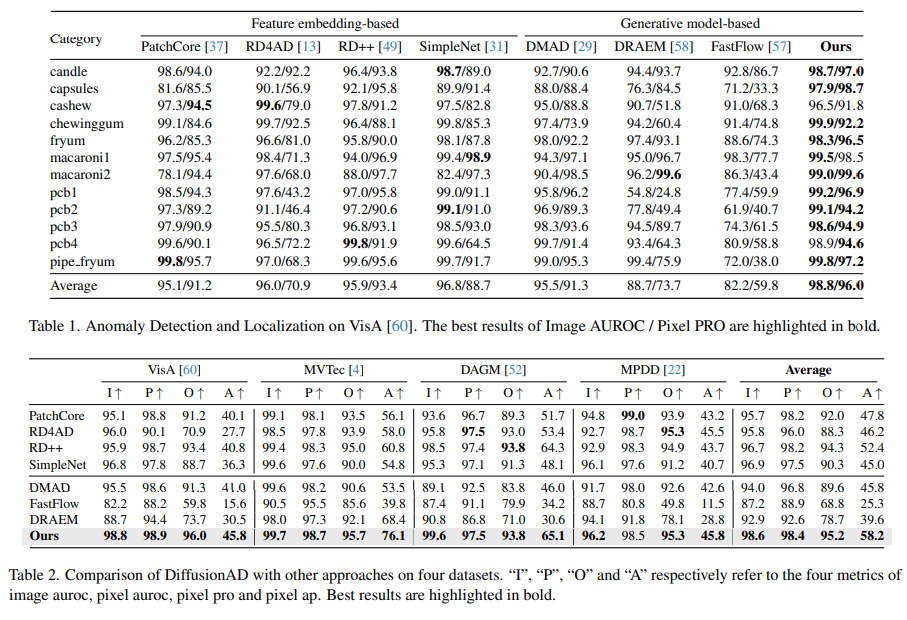
Table 1과 2에서 확인할 수 있듯이, 다른 모델들과 꽤 큰 차이로 훌륭한 성능을 입증했다. Intro에서 확인한 Inference 속도까지 감안했을 때, 아주 우수하다고 생각된다.
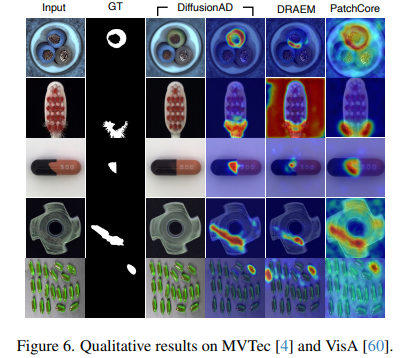
Figure 6를 보면, reconstruction sub-network가 여러 타입의 anomalies에 대해도 매우 잘 작동함을 보여준다.
(물론 다른 모델과 확연하게 차이가 잘 보이는 결과만 보여줬을 수 있다 ㅎ)
Ablation Study
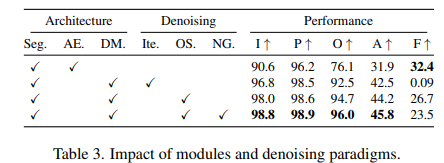
Table 3의 결과에서는
1) 해당 태스크에서 기본적으로, AE < DM의 성능을 확인할 수 있고,
2) One-step Denoising을 적용하면 AE에 비해 느리긴 하지만, DM도 어느정도 처리 속도가 빠름을 알 수 있다.
3) DM+OS+NG의 경우는 당연히 앞서 확인한 결과처럼 우수한 성능을 보인다.
+ 4) 개인적인 궁금증으론 Iterative의 경우 생성 이미지의 퀄리티 자체는 더 낫지 않을까..?

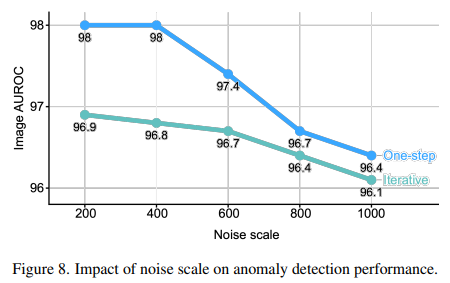
Figure 7과 8을 통해 noise scale이 커질수록 reconstruction quality가 떨어지고, AD 성능도 감소함을 확인할 수 있다.
[참고 자료]
[1] Zhang, Hui, et al. "DiffusionAD: Denoising Diffusion for Anomaly Detection." arXiv preprint arXiv:2303.08730 (2023).
[2] Xuebin Qin, Hang Dai, Xiaobin Hu, Deng-Ping Fan, Ling Shao, and Luc Van Gool. Highly accurate dichotomous image segmentation. In ECCV, 2022