Report: https://arxiv.org/abs/2601.17237
C-RADIOv4 (Tech Report)
By leveraging multi-teacher distillation, agglomerative vision backbones provide a unified student model that retains and improves the distinct capabilities of multiple teachers. In this tech report, we describe the most recent release of the C-RADIO famil
arxiv.org
엔비디아가 강력한 성능과 효율성을 겸비한 새로운 Vision Foundation Model을 공개했다.
다른 빅테크 기업이 모델 사이즈를 점점 키우는 동안, 엔비디아는 거대 모델의 능력을 (비교적) 작고 빠른 모델에 압축해 공개했다.
Motivation
1. 최신 Vision Foundation Model의 장점
엔비디아는 이미 성능이 입증된 Foundation model을 Teacher Model로 활용해 RADIO 시리즈를 업그레이드 하고자 했다.
Teacher model로 사용된 foundation model은 각기 다른 장점을 갖는다.
- SigLIP2: Text-Image Alignment
- DINOv3: Dense Prediction
- SAM3: Segmentation
2. 기존 Distillation 방식의 한계
C-RADIOv4는 뛰어난 Teacher model들의 장점을 통합하고, 기존 Distillation 방식의 한계를 해결하고자 했다.
1) fixed pattern noise
Teacher model들(특히, DINO, SAM)은 이미지의 내용과 무관하게 특정 노이즈 패턴(Artifacts) 및 경계 부분의 결함을 가짐. Student model이 이를 그대로 학습시, 성능 저하
2) loss 불균형
여러 Teacher model을 도시에 학습시, 특정 Teacher model의 Feature vector의 분산이 커져 Training loss를 지배
3) 해상도 mode switching
해상도에 따라 representation이 일관되지 않고 추론 성능이 불안정
Method
1. Updated Teachers
SigLIP2-g-384, DINOv3-7B, SAM3를 Teacher Model로 사용했다.
2. Stochastic Resolutions
기존 RADIOv2.5이 두 개의 고정된 해상도로만 학습했던 것과 달리, C-RADIOv4는 다양한 해상도를 샘플링해 학습하는 방식을 도입했다.

이 학습 방식의 효과로 저해상도에서의 품질 향상 뿐 아니라 학습된 해상도보다 더 높은 해상도에 대해서도 성능이 향상됐다.
3. Shift Equivariance
Teacher Model들이 가진 Fixed pattern noise를 Student Model이 그대로 학습하는 것을 방지하기 위해, 1) Shift Equivariance Loss 와 2) Shift Equivaraint MESA를 도입했다.
1) Shift Equivariance Loss

Teacher와 Student가 보는 Crop Image를 서로 독립적으로 미세하게 이동(Shift)시킨다.
이를 통해 Student 모델이 Fixed pattern noise를 학습하지 않게 된다.
2) Shift Equivaraint MESA

Model의 일반화 성능을 높이는 MESA(Sharpness-aware training) 기법을 응용, Fixed pattern nosie 발생을 억제
4. DAMP
학습 중에 Model의 Weights에 Multiplicative nosie를 적용하는 DAMP 방식을 적용해, Robustness를 더욱 강화
5. Balanced Summary Loss
특정 Teacher model이 training loss를 지배하는 현상을 막기 위한 새로운 Loss를 도입했다.
기존에는 Summary Features를 Cosine Similarity로만 매칭했는데, 이때 Teacher model마다 feature가 형성하는 cone의 radius가 상이해, radius가 더 큰 Teacher model이 더 큰 Loss를 만들고 학습을 지배한다.

따라서, 각 Teacher model의 angular dispersion을 계산(아래 수식의 Disp)해 cone radius between teacher models를 정규화하기 위해 사용한다.

* 각 Teacher model간 차이

Result
1. Metrics
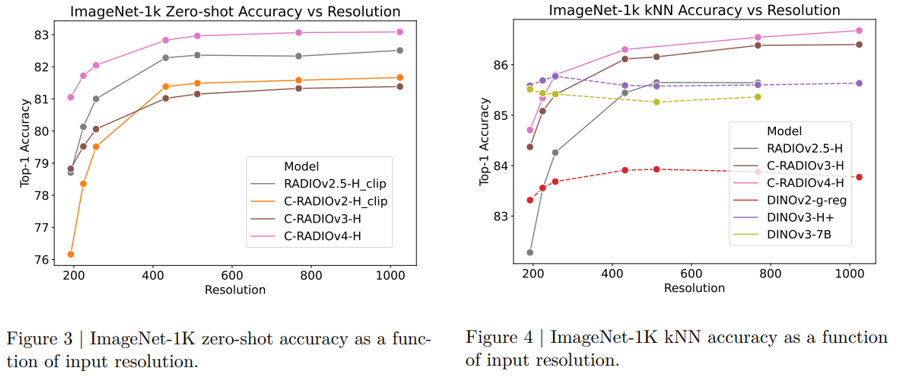
우선, 낮은 해상도부터 고해상도까지 성능을 기존 모델 대비 크게 개선했을 뿐 아니라 DINO와 달리 해상도가 높아져도 성능이 유지되거나 향상되는 것을 확인할 수 있다.
2. SAM3
C-RADIOv4는 SAM3의 vision encoder를 대체할 수 있도록 설계됐다.

C-RADIOv4를 사용해도 텍스트 프롬프트를 통한 객체 분할이 정확하게 수행되는 것 또한 확인할 수 있다.

또한 추론 속도를 높이는 ViTDet 모드를 지원한다.

Fig 5를 보면, ViTDet 모드를 사용하면 고해상도에서도 Latency 증가 폭이 훨씬 완만하여 효율적인 것을 확인 가능하며, Fig 9을 보면 ViTDet 윈도우 크기에 따라 SAM3보다 빠른 추론이 가능함을 보인다.

추가로, SAM3 공개 코드에는 'person' 쿼리가 제대로 작동하지 않는 버그가 있으나, C-RADIOv4로 Backbone을 교체하면 이 문제가 해결되는 것을 확인할 수 있다.

4. 기타 사항
이전 모델보다 Object boundaries가 훨씬 선명해진 것을 확인할 수 있다. (픽셀 단위 더 정교한 인식)

Teacher model인 DINOv3가 가진 고질적인 Fixed pattern noise가 해결된 것도 확인할 수 있다. (장점만 학습)

Contribution
1. 높은 실용도
고해상도 추론 효율성을 확보해 실제 산업(자율주행, 로보틱스 등)에서의 활용도를 높였으며,
고성능 경량화 모델 C-RADIOv4 (SO400M, Huge)을 상업적으로 사용할 수 있는 Permissive license로 공개했다.
2. Distillation 방법론
Student Model이 Teacher Models를 모방하는 것을 넘어 장점은 통합, 발생할 수 있는 문제는 예방할 수 있는 방법을 제시했다.