Paper: https://arxiv.org/abs/2201.12086
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has bee
arxiv.org
Github: https://github.com/salesforce/BLIP
GitHub - salesforce/BLIP: PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understan
PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation - GitHub - salesforce/BLIP: PyTorch code for BLIP: Bootstrapping Language...
github.com
Introduction
Vision-Language Task에 대한 연구가 활발해지고, 이런 Task를 수행하기 위한 모델의 학습에는 Image-Text Pair를 수집한 대용량 데이터가 필수적이다.
Web에서 데이터를 수집하면 대용량의 데이터를 얻을 수는 있으나, Noise가 매우 많다.
결국 질 좋은 Large Scale Web Dataset으로 모델을 Pretraining 시키고 싶다는 Needs가 있고, 이를 위해 저자들은 이미지의 Caption을 생성하는 Captioner와 이미지의 Noisy Caption을 제거하기 위한 Filter를 활용한다.

Method
Multimodal Mixture of Encoder-Decoder (MED)

BLIP은 크게 세가지 Task를 수행해 Pretraining이 이뤄진다.
CapFilt
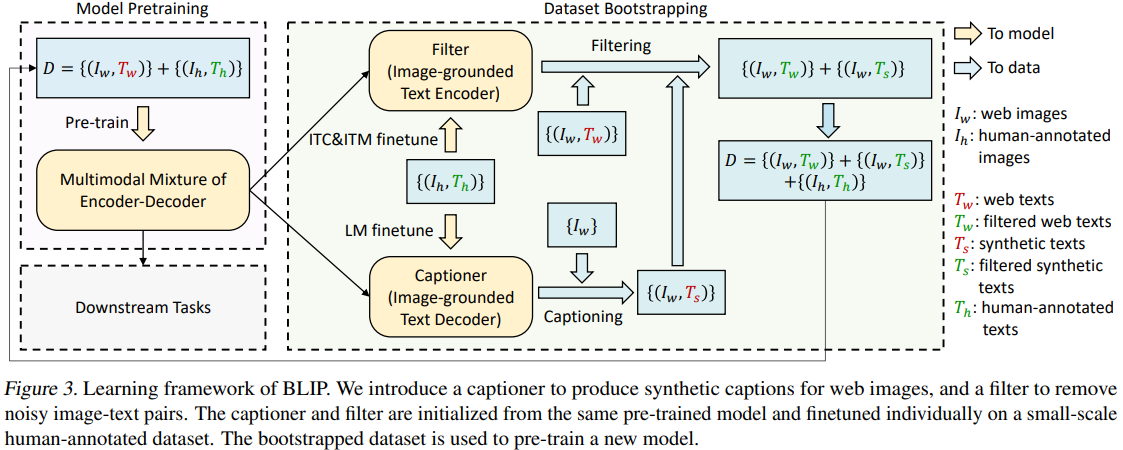
이렇게 얻은 Captioner와 Filter를 통해 Noise를 제거한 새로운 데이터셋 생성 후, 다시 MED를 Pre-training 하고 이후 Downstream Task를 위해 활용한다.