Paper: https://arxiv.org/abs/2410.10604
Multi-modal Vision Pre-training for Medical Image Analysis
Self-supervised learning has greatly facilitated medical image analysis by suppressing the training data requirement for real-world applications. Current paradigms predominantly rely on self-supervision within uni-modal image data, thereby neglecting the i
arxiv.org
CVPR 2025에 게재된 논문이다. 코드는 아래에서 확인 가능하다.
https://github.com/EIT-NLP/Layer_Select_Fuse_for_MLLM
GitHub - EIT-NLP/Layer_Select_Fuse_for_MLLM: [CVPR2025] Official implementation of the paper "Multi-Layer Visual Feature Fusion
[CVPR2025] Official implementation of the paper "Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices". (by Junyan Lin) - EIT-NLP/Layer_Select_Fuse_...
github.com
연구 배경과 어떤 방법을 활용했는지 간단히 확인만 해보겠다.
1. Introduction
Multimodal LLM에서 Visual Information을 활용하는 것이 매우 중요하지만, 어떤 Visaul Layer를 selection하고 Fusion할지에 대한 연구는 부족하다.

따라서 이 페이퍼에서는 아래 두 가지를 다룬다.
1) Selecting the most effective visual layers
2) Identifying the best fusion approach with the language model
Fig 1에선 MLLM에서 Visual Feature를 어떻게 활용하고, Text와 Fusion하는지 다양한 패러다임을 보여준다.

2. Method
Visual Layer Selection
이 페이퍼에서는 Fig 2의 두 방식으로 Layer를 Selection하는 방식을 나눴다.

- Similarity-based selection: 코사인 유사도에 따라 비주얼 인코더의 레이어를 ‘beginning’, ‘middle’, ‘ending’ 3개 그룹으로 구분하고, 각 그룹을 대표하는 Layer(예: 3, 18, 23)에서 Feature를 추출
- Proportion-based selection: Layer를 Encoder의 Depth에 비례하도록 나눠서 'former’, ‘latter’로 나누어 선택된 부분의 Layer에서만 Feature를 추출
Fusion
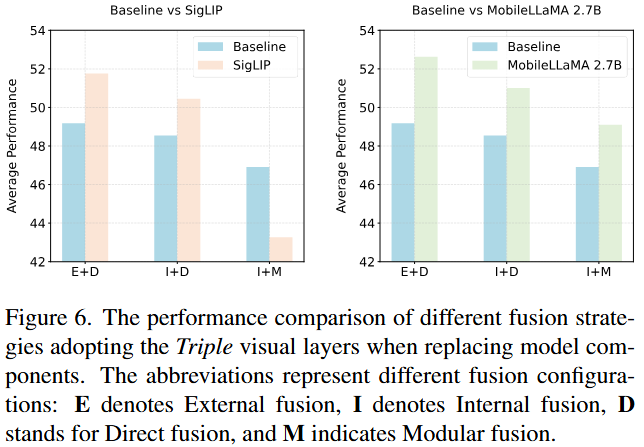
Fusion 방식은 Internal vs External, Modular vs Direct 중 어떤 것을 선택하냐에 따라 Fig 3와 같이 4가지로 나뉜다.

3. Experimental Result
이 논문은 많은 실험을 수행했고, 그 결과를 정리했다. 하나씩 확인해보겠다.
1) Beginning, Middle의 조합(Double)이 단일 또는 Ending layer를 추가로 사용할 때보다 전반적으로 일반화 성능이 뛰어나다.

2) External Fusion 자체가 일반적으로 Internal Fusion 대비 더 우수했다. External Fusion에서는 Direct Fusion 만으로도 Multi-Layer Visual Feature 통합이 효과적이다.

3) External Fusion은 일반적으로 더 적은 데이터로 더 나은 결과를 보이고, Internal Fusion은 데이터가 늘어날수록 성능 향상 폭이 커져, 대규모 학습이 필요

4) 강력한 Visual Encoder와 더 큰 LLM을 사용할수록 External Fusion, 특히 External & Direct 방식이 뛰어남을 확