Paper: https://arxiv.org/abs/2410.05440
Can LLMs Understand Time Series Anomalies?
Large Language Models (LLMs) have gained popularity in time series forecasting, but their potential for anomaly detection remains largely unexplored. Our study investigates whether LLMs can understand and detect anomalies in time series data, focusing on z
arxiv.org
ICLR 2025에 submit된 논문으로, 관련 Code는 아래 Github에서 확인할 수 있다. (현재 Poster Accept)
https://github.com/Rose-STL-Lab/AnomLLM
GitHub - Rose-STL-Lab/AnomLLM
Contribute to Rose-STL-Lab/AnomLLM development by creating an account on GitHub.
github.com
1. Introduction
이미, LLM을 Time series analysis에 적용한 연구들이 있다.
특히, forecasting 및 classification task에는 zero-shot 또는 few-shot learners로서의 가능성을 보였다.
(time series를 숫자 문자열로 인코딩하는 등의 방식으로 입력 후 task를 수행하는 등의 예시가 있음.)

하지만, simpler model이 더 나은 성능을 보이는등 LLM-based time series analysis approach에 대해서는 여전히 의문이 많은 상태이다. 이는 결국 LLM이 시계열 데이터를 제대로 이해하는가?라는 질문으로 이어진다.
이 논문에서는 LLM이 시계열 데이터를 제대로 이해하는지, 이상을 탐지할수 있는지에 대해 논의하며 LLM과 Multimodal LLM이 다양한 anomaly type에 대해 어떻게 작동하는지 분석했다.이 논문은 여러 가설에 대한 검증을 수행하는데, 결론을 요약하면 다음과 같다:
- Visual Advantage: LLM은 텍스트 표현보다, 시각화된 time series data를 처리할 때 오히려 성능이 향상된다.
- Limited Reasoning: LLM은 시계열 데이터를 분석시 complex reasoning을 하지 않으며, reasoning을 요구하는 prompt 기법이 적용되면 오히려 성능이 저하될 수 있다.
- Non-Human-Like Processing: LLM의 anomaly detection은 인간의 인식과는 다르며 LLM은 인간이 놓칠 수 있는 trend를 식별 가능하고, 모델의 arithmetic abilites와 성능은 관련이 없다.
- Model-Specific Capabilites: LLM 아키텍쳐에 따라 time series understanding and anomaly detection capabilities에 차이가 있다. 따라서, 모델 선택이 중요하다.
2. Time series anomaly detection: definintion and categorization
저자들은 time series anomaly detection을 명확히 논의하기 위해 일부 관련 내용을 정의하고, anomaly type을 categorization 했다.
2. 1. Time series anomaly detection definition
우선 anomalies는 expected pattern에서 현저히 벗어난 data point를 말하며, 이를 Generating Function에 따라 두 방법으로 정의할 수 있다.
Deterministic
예측값과 실제값의 차이가 일정 threshold를 넘는 경우
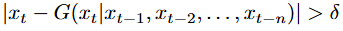
Stochastic
관측값을 기반으로 예측값이 나타날 확률이 일정 threshold보다 낮은 경우

2. 2. Time series anomalies categorization
Anomaly type은 크게 2가지로 나눠지고 세부 항목을 포함해 총 4가지로 나눠진다.

Contextual anomalies
Cotnextual anomalies는 time series의 pattern에서 벗어난 data points 또는 subsequences를 나타낸다. (시간 순서가 중요하기에 time series의 순서가 보존될 때만 감지 가능하며, 순서가 섞이면 감지할 수 없다.)
- Trend: 전반적인 방향이나 변화율이 예상되는 trend와 다를 때 (갑작스러운 가속 또는 감속의 변화 등)
- Frequency: frequency적 요소가 예상하는 pattern과 다를 때, 주로 frequency domain에서 분석해 감지 가능
- Contextual Point: 극단적인 이상치는 아니지만, local context에 맞지 않을 때
Out-of-range anomalies
Out-of-range anomalies는 time-series에서 다른 data points들과 값이 매우 멀리 떨어져 있는 개별 data point를 말한다.
Contextual anomalies와는 달리, 시간 순서보다는 값 자체에 집중하기에 이러한 이상은 순서가 섞여도 감지할 수 있다.
3. Understanding LLM's UNDERSTANDING OF TIME SERIES
3. 1. Hypothesis
저자들은 LLM의 이상 탐지 능력을 평가하기 위해, 기존의 연구들에서 제시된 가정을 정리해 7가지로 제시한다.
1. CoT를 사용해도 시계열에 관한 성능이 향상되지 않음.

2. LLM의 repetition bias(반복적으로 같은 토큰을 생성하는 경향)은 시계열에서 주기성을 인식하는데 관련이 있다.

3. LLM의 arithmetic 관련 성능은 linear 및 exponential trends의 extrapolation과 연결된다.

4. 시계열 이상치는 text input보다 visual input으로 주어졌을 때 더 쉽게 detect된다.

5. LLM의 understanding of anomalies는 인간의 시각적 인식과 일치한다.

6. LLM은 시계열에 대해 정보를 잃을 수 있어도 token수가 적을 때, 더 나은 성능을 보인다.

7. 다른 Architecture를 가진 LLM이어도 시계열에 대한 이해는 consistent하다.

3. 2. Prompting Strategies
이 연구에서는 Zero-shot 그리고 Few-shot learning과 CoT(Chain of Thought)을 활용해 LLM의 시계열 이상 탐지 성능에 대한 실험을 수행한다.
이 논문에서의 CoT는 주로 아래의 템플릿으로 구성된다:
(1) LLM에게 일반적인 시계열 패턴(주기적 파동, 증가하는 추세)등을 설명
(2) 패턴에서의 이탈을 식별하는 방법을 설명
(3) 이탈이 dataset's normal behaviors에 의거해 이상인지 판단하는 방법을 설명
Input Representation
저자들은 연구에서, 시계열 데이터를 입력하는 방법에 따른 차이도 strategies를 나누어 검증했다. (모두 매우 간단한 세팅이다.)
Textual Representation으로는
(1) Original: 시계열 값을 ,로 구분해 입력
(2) CSV: CSV 형식의 데이터 (index and value per line) 입력
(3) Prompt as Prefix: 시계열 window별로 mean, median, trend를 추출해 Original Data와 함께 입력
(4) Token per Digit: 부동 소수점 숫자를 공백으로 구분해 처리 후 입력 (ex: 246 -> 2 4 6)
Visual Representation으로는
(1) 시계열을 plot한 뒤 multiomdal LLM에 입력 (github Repo를 보면 예시를 볼 수 있는데 매우 간단하다.)
Output Format
LLM의 Prompt에 Output Format에 대한 형식을 요구한다. JSON 형식으로 아래와 같이 이상의 시작 시점과 끝 시점을 출력하도록 한다.

4. Experiment
실험은 당시 SOTA인 Multimodal LLM 모델들을 대상으로 수행했으며, 저자들이 category를 나눈 anomaly type에 맞게 Synthetic Dataset을 만들어 수행했다.
결과 Table, Figure를 보며 각 Hypothesis에 대해 어떤 결론이 났는지 훑어보겠다. (실험에 따라 제시된 가설이 맞다고 판단한 경우 초록색, 틀렸다고 판단한 경우 빨간색)
1. CoT를 사용해도 시계열에 관한 성능이 향상되지 않음.
CoT를 사용했을 때 유의미한 성능 향상은 없었으며, 오히려 성능이 떨어지는 경우 발생해 가설을 Accept.

2. LLM의 repetition bias(반복적으로 같은 토큰을 생성하는 경향)은 시계열에서 주기성을 인식하는데 관련이 있다.
저자들은 Repetiton bias가 영향을 미쳤다면, 원 Time series에 Noise를 주입했을 때, 성능 하락이 발생할 것으로 예상하고 실험을 세팅했다. 하지만 Noise를 추가해 반복되는 Token을 적게해도 성능 하락은 발생하지 않았고, 가설은 Reject 됐다.

3. LLM의 arithmetic 관련 성능은 linear 및 exponential trends의 extrapolation과 연결된다.
이 가설 검증을 위해, LLM의 5자리 정수 덧셈 정확도가 12% 떨어지도록하고 실험했으나, 성능은 안정적이었다. 따라서 가설은 Reject 됐다.

4. 시계열 이상치는 text input보다 visual input으로 주어졌을 때 더 쉽게 detect된다.
Frequency Anomaly를 제외하고는 Time series를 Image로 입력했을 때(Visual Input) 성능이 더 뛰어난 것을 확인했다. 따라서 Accept.

5. LLM의 understanding of anomalies는 인간의 시각적 인식과 일치한다.
저자들은 육안으로는 확인하기 어려운 Flat Trend Dataset을 만들고, 실험을 수행했다. LLM은 해당 환경에서도 Anomalies를 포착할 수 있었다. 따라서 가설은 Reject 됐다.

6. LLM은 시계열에 대해 정보를 잃을 수 있어도 token수가 적을 때, 더 나은 성능을 보인다.
Subsampled time series에 더 뛰어난 성능을 보였고, Accept

7. 다른 Architecture를 가진 LLM이어도 시계열에 대한 이해는 consistent하다.
각 LLM에 따라 실험 결과가 일관되지 않았다. 따라서 Reject이며, Time series와 관련해 LLM을 활용하려면 모델별 여러 실험이 필요해보인다.
참고자료
[1] https://arxiv.org/abs/2410.05440, Can LLMs Understand Time Series Anomalies?
[2] https://arxiv.org/abs/2310.07820, Large Language Models Are Zero-Shot Time Series Forecasters