Paper: https://dl.acm.org/doi/10.1145/3649447
ACM Computing surveys에 게재된 survey paper다.
Multimodal Data Fusion에 대해 정리할 필요가 있었는데, 해당 논문이 좋은 참고자료가 됐다.
1. Introduction
Conventional taxonomy
전통적으로는 아래와 같이 Multimodal Data Fusion 분류하고, 다루는 연구들이 많다. 최근 페이퍼들을 봐도 연구자들이 많이 사용하는 분류 체계인 것 같다.

Early Fusion (조기 융합)
서로 다른 modality의 raw data 또는 전처리된 데이터를 모델에 입력하기 전에 융합하는 방법이다. (이미지에서 Modality 1과 Modality 2의 데이터가 Feature Extractor를 거치기 전에 합쳐지는 것을 볼 수 있다.)
Early Fusion은 modality 간의 상호 작용을 초기에 고려할 수 있다는 장점이 있지만, 서로 다른 modality의 특성을 제대로 반영하지 못할 수 있다는 단점이 있다.
Intermediate Fusion (중간 융합)
각 modality에서 추출된 feature들을 융합하여 모델의 중간 단계에서 결합하는 방식이다. (이미지에선 Modality 1, 2, N에서 각각 Feature Extractor를 거쳐 추출된 특징들이 중간에서 합쳐지는 것을 확인할 수 있다.)
이 방식은 각 modality의 특징을 개별적으로 학습한 후 Fusion하므로, Early Fusion보다 유연하게 modality 간의 관계를 학습할 수 있다.
Late Fusion (후기 융합)
각 modality를 독립적으로 처리한 후, 각 modality에서 얻은 최종 결정(decision)들을 결합하여 최종 예측을 수행하는 방식이다. (이미지에서 Decision 1, 2, 3이 독립적으로 이루어진 후 최종적으로 합쳐져 Final Decision을 내리는 것을 볼 수 있다.)
Late Fusion은 각 modality의 독립적인 의사 결정 과정을 보장하지만, modality 간의 복잡한 상호 작용을 놓칠 수 있다는 한계가 있다.
Proposed taxonomy
본 논문에서는 Deep Multimodal Data Fusion에서 주로 사용되는 기술을 다섯 가지 그룹으로 나눠 설명한다.

Figure 5에 나와있듯, 다섯 가지는 아래와 같다.
1. Encoder-Decoder Methods
2. Attention Mechanism Methods
3. Graph Neural Network Methods
4. Generative Neural Network Methods
5. Constraint-based Methods
이번 리뷰에서는 이중 내가 추후에 활용할 가능성이 가장 높다고 생각되는
1. Encoder-Decoder based Fusion, 2. Attention based Fusion 두가지에 대한 부분만 읽고 정리하고자 한다.
2. Encoder-Decoder based Fusion
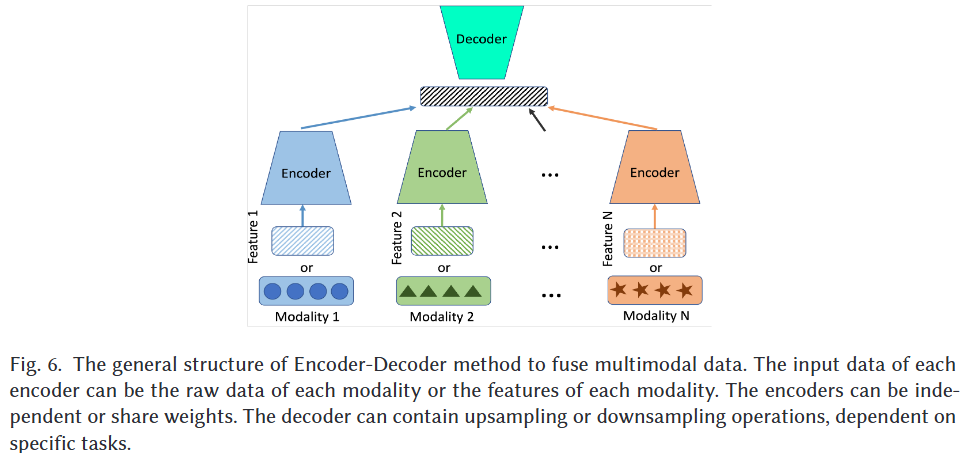
Fig 6에 나온 General Structure와 같이, Encoder-Decoder 구조에서는 다양한 modality의 data로부터 얻은 high-level feature들이 latent space로 projection되고, 이후 Task-specific decoder는 latent representation으로부터 예측을 수행한다.
실제 시나리오에서는 아래 Fig 7과 같이 다양한 구조적 변형이 존재한다.

논문에서는 2개 Modality의 Feature를 합치는(Merge) 방법을 M으로 표현하는데, 이 연산들은 Fig 8에서 확인할 수 있다.

이러한 연산들은 task와 데이터의 특성 그리고 Feature를 어떻게 다루고 싶은지를 고려해 사용하면 된다.
예시로,
- element-wise add/multiply는 feature간의 상호 작용을 간단히 모델링하는 데 유용하며
- concatenation은 각 feature의 정보를 그대로 유지하면서 결합하는 데 적합하고
- cross product는 Feature간의 복잡한 상호 작용을 모델링하는 데 사용될 수 있지만, 계산 비용이 높다는 단점이 있다.
Raw-data-level Fusion
Raw data 또는 독립적인 전처리 과정을 거친 데이터를 Input 수준에서 통합하는 것을 의미한다.
각 Modality의 데이터를 Fusion해 하나의 입력 벡터를 생성하고, 이 입력 벡터를 하나의 Encoder에 전달해 high-level feature를 추출한다.
장점: 각 modality의 Original Information을 최대한 보존할 수 있고, 단일 backbone을 사용해 computational cost를 줄일 수 있다는 장점이 있다.
단점: 반면에, Modality의 수가 증가하면 input data 자체의 차원이 매우 커질 수 있다. 이런 특성으로 인해 주로 두 modality의 fusion에 많이 사용되는 편이다.
Hierarchical Feature Fusion
신경망의 Hierarchical Feature를 사용하는 방식이다.
서로 다른 level에서 추출된 feature를 융합해 모델 성능을 향상시키는 데 목적이 있다.
장점: Fusion이 일어날 level과 얼마나 많은 level에서 Fusion을 할 것인가를 결정할 수 있는 Flexibility 측면에서 장점이 있다. 또한, attention mechanism 과 결합하기 용이하다.
단점: 반면에, Modality의 수가 증가하면 그림에도 나와있듯 modality에 대한 각 개별 Encoder를 활용하니 Computational cost가 증가한다.
Decision-level Fusion
개별 Modality의 Decoder 또는 Classifier의 마지막 단계에서 Fusion이 이뤄지는 방식이다.
즉, Modality 간 정보 교환이 decoder의 마지막 layer 또는 그 바로 앞 layer에서 발생한다.
장점:구현이 비교적 간단하고, 각 modality가 최종 결정에 미치는 기여도(relative contribtuion weight 이라고 논문에서 표현)를 파악하기 쉽다. 또한 각 modality의 prediction result에 대한 판단도 가능하다.
단점: 반면에, 전체 성능이 특정 modality에 의해 제한될 수 있고 modality간 정보를 통합하는 방식이 유연하지 못하다.
3. Attention based Fusion
이름 그대로, Attention mechanism에 기반한 Fusion 방법이다.
Multimodal Data Fusion시, 각 Modality간 중요도, 각 Modality의 관계 내 중요도 등을 고려할 수 있어 모델이 다양한 Modality 간의 관계를 더 잘 이해하고 활용할 수 있다.
논문에서 표현하듯, 현재는 multimodal data fusion task의 main tool로 생각된다.

Fig 10에서 다양한 Attention Mechanism과 Fusion 아키텍쳐를 확인 가능하며, 각 방법에 대해서 다뤄보겠다.

Intra-modality Self-attention
특정 Single Modality 내의 관계를 파악하는 데 중점을 둔다. 즉, 각 modality 자체의 데이터에만 attention을 활용해 내부적인 특징을 추출한다.
장점: 하나의 Modality만 고려하면 되기 때문에 유연하고 구현이 용이하며 계산 비용이 비교적 저렴하다.
단점: Modality 간의 상호 보완적인 관계를 간과할 수 있다. 모델 성능 향상에 기여할 수 있는 modality 간 관계를 활용하지 못할 수 있다.
Inter-modality Cross-attention
서로 다른 modality 간의 관계를 파악하는 데 초점을 맞춘 attention 메커니즘이다. Attention score는 여러 modality의 데이터를 활용해 계산된다.
Fig 10 (c)의 Cross Attention을 보면 Query, Key, Value가 다른 modality로부터 파생된다. 예를 들어, 이미지 modality의 정보가 Query로 사용되고텍스트 modality의 정보가 Key, Value로 사용될 수 있다.
장점: 여러 Modality간의 복잡한 상호작용을 모델링하는 데 효과적이다.
단점: 계산 복잡성이 증가할 수 있다. Modality간 Assigne이 제대로 되지 않은 경우 성능이 저하될 수 있다.
Transformer-based method
Self-attention을 핵심으로 사용하는 Transformer에 기반한 방법이다. 입력 데이터의 모든 sequences를 고려해 local한 특징을 고려함과 동시에 long-range dependencies를 효과적으로 포착한다.
장점: Transformer 기반 모델은 다양한 modality에 대한 포괄적인 representation을 학습하고, 일반적으로 다른 모델들보다 downstream task에 뛰어난 성능을 보인다.
단점: 단점이라기 보다는 연구 트렌드의 문제인데, 대부분의 pre-trained model이 Vision-Language Task에 집중돼 있다.
4. Appendix
Table 1을 확인하면 어떤 Transformer Architecture, Modality를 활용한 선행 연구들이 있었는지 쉽게 확인할 수 있다.

또한 아래와 같이 Dataset에 대해 정리된 자료도 필요시 참고하기 좋을 것 같다.
